Matches
Matchwerte stellen die Grundlage für die Kalkulation und Abrechnung von Übersetzungsprojekten dar. Vergleicht man die Kennzahlen in den Reports bzw. Analysen verschiedener CAT-Tools, kann man sowohl grosse Ähnlichkeiten als auch nennenswerte Unterschiede bezüglich Kategorisierung feststellen. In diesem Artikel möchten wir Ihnen daher die typischen Matchwertkategorien der Reports in Across näherbringen und einige interessante Details vorstellen.
Sämtliche Beobachtungen basieren auf einem sog. Master Data Report (MDR).
Dieser Report enthält alle Stammdaten zu einem Projekt, eingecheckten Dokumenten und Aufgaben, und unterteilt sich in einen projekt- und einen dokumentbezogenen Teil:
- Projekt: z. B. Erstellungs- und Abschlussdatum, gewählte Relation;
- Dokument: z. B. Dateiformat, gewähltes Fachgebiet, zugrundeliegender Workflow).
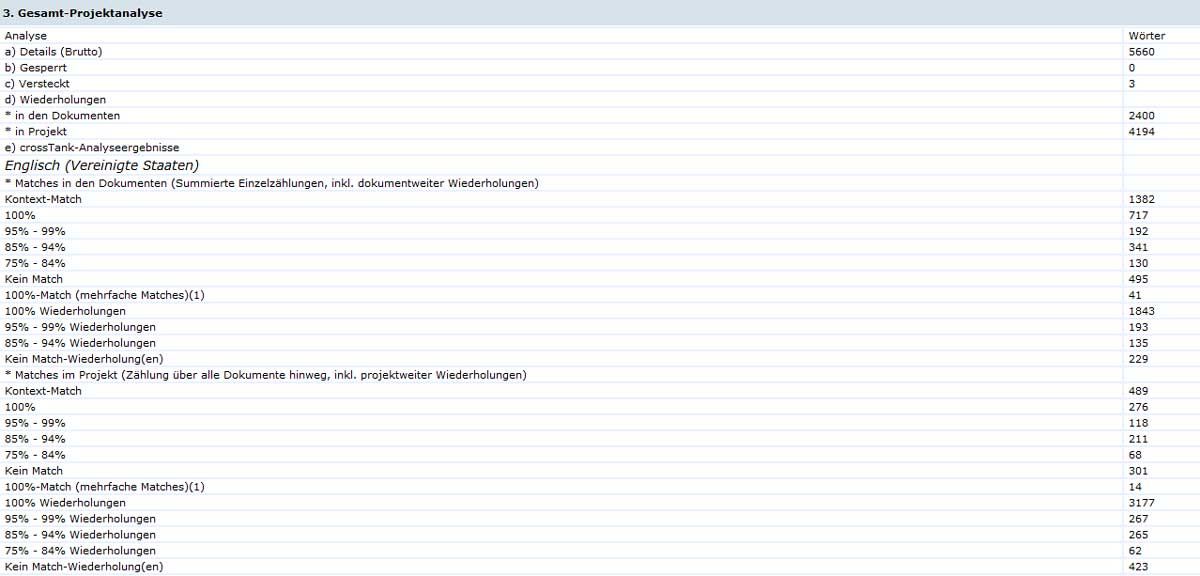
Für eine Betrachtung der verschiedenen Matchwertkategorien gibt der Abschnitt Gesamt-Projektanalyse alle wichtigen Informationen.
Matches – was war das noch mal?
Seit Einführung von Translation Memory-Systemen sind Matches/Matchwerte ein gängiger Begriff und der Kennwert für die Berechnung von Übersetzungskosten und Bearbeitungsdauer. Wird in einem CAT-Tool ein neues Übersetzungsprojekt angelegt, findet ein Vergleich des aktuell zu übersetzenden Dokuments mit dem Translation Memory (im Falle von Across: dem crossTank) statt. Ist ein Ausgangssegment in identischer oder ähnlicher Form schon einmal in der gewünschten Sprachkombination übersetzt worden, wird diese Übersetzungseinheit gefunden und als Suchtreffer ("Match") im Report ausgewiesen.
Doch Match ist nicht gleich Match, und hier kommen wir wieder zum Fokus dieses Artikels. Matches können von unterschiedlicher Qualität sein und sich u. a. in ihrer Match-Quote, d. h. ihrem Grad der textlichen Übereinstimmung zwischen aktuellem Ausgangssegment und im TM gefundener Übersetzungseinheit, unterscheiden. Typischerweise wird diese Match-Quote in Prozent angegeben. Neben textlichen Unterschieden können zudem auch abweichende Formatierungen (z. B. eine fehlende Fett-Formatierung) zu einer niedrigeren Match-Quote führen.
Eine der häufigsten Matchwertkategorien ist das 100%-Match (auch: "Full Match" genannt); hier wird eine vollständige Übereinstimmung hinsichtlich Text und Formatierung zwischen dem Ausgangssegment und einer vorhandenen Übersetzungseinheit festgestellt. Ist kein exakter Suchtreffer in crossTank zu finden, werden die gefundenen Übersetzungseinheiten ihrer Match-Quote nach abgestuft. Diese sogenannten Fuzzy-Matches bewegen sich in der Regel in einem Bereich von 99% bis 50% Übereinstimmung. Wirklich neu zu übersetzende Segmente finden sich in der Kategorie Kein Match; diese Segmente liegen unterhalb der Mindestmatching-Quote von üblicherweise 50%. Sämtliche Matching-Bereiche können jedoch individuell eingestellt werden.
Die Grundlagen
Details (Brutto)
Eine der ersten Kennzahlen in einem Report sind die Gesamtwörter (Details (Brutto)). Diese Zahl beinhaltet alle im Dokument enthaltenen Wörter, ungeachtet ihres Matchwertes oder ihrer Bearbeitbarkeit in crossDesk (d. h. in dieser Zahl sind auch alle gesperrten oder versteckten Segmente enthalten, die vom Übersetzer gar nicht berührt werden).
Details (Netto)
Eine genauere Kennzahl stellt Details (Netto) dar. Diese Kennzahl enthält alle Wörter exkl. gesperrter, versteckter oder sich wiederholender Einheiten, Kontext-Matches und sämtlicher Arten von 100%-Matches (hierzu später mehr).
Wiederholungen
Spricht man von sich wiederholenden Einheiten, so ist hiermit die Summe aller Wiederholungen gemeint, ohne Zählung des ersten Vorkommens eines Ausgangssegmentes. Unterschieden wird zwischen Wiederholungen in den Dokumenten und im Projekt. In der Regel werden bei einer projektweiten Zählung der Wiederholungen höhere Werte erreicht als bei einer dokumentenseparaten Zählung, da bei ersterer Variante Wiederholungen über alle eingecheckten Dokumente hinweg berücksichtigt werden. Wird eine Zählung in den Dokumenten gewählt, werden die Wiederholungen pro Dokument ausgezählt und als Teilsummen addiert. Diese Unterscheidung nach Dokumenten und Projekt im Report gilt im Übrigen für alle Matchwertkategorien (inkl. bei der Übersetzung erst entstehender Fuzzy-Matches).
Analog zu den bereits erläuterten Matchwertkategorien werden Wiederholungen ebenfalls gemäss ihrer Matching-Quote abgestuft – man spricht daher von Match-Wiederholungen, da die vorhandenen crossTank-Suchtreffer berücksichtigt werden. Unter 100%-Wiederholungen versteht man Wiederholungen sämtlicher Arten an 100%-Matches (z. B. MÜ-Matches, Matches aus bilingualen Dateien), Kontext-, Struktur- oder kombinierten Matches aus den beiden Kategorien. Wiederholungen für Suchtreffer niedrigerer Matching-Bereiche (z. B. 95-99%-Wiederholungen) entsprechen der in den Systemeinstellungen festgelegten Staffelung. Dementsprechend handelt es sich bei Kein Match-Wiederholungen um Wiederholungen, für die keine Matches in crossTank gefunden werden konnten. Alle Arten der Match-Wiederholungen ergeben dann die Gesamtzahl der Wiederholungen in den Dokumenten bzw. im Projekt.
Ein 100%-Match kommt selten allein
In der Kategorie der bereits erwähnten 100%-Matches werden hinsichtlich verschiedenster Kriterien (z. B. Ursprung des Matches) noch folgende Unterarten unterschieden:
- 100%-Match / nicht eingefügt (Mehrfache Matches): Für den vorliegenden Ausgangstext sind mehrere 100%-Matches vorhanden. Eine Vorübersetzung erfolgt in diesem Fall in der Regel nicht, kann aber in den Profileinstellungen erzwungen werden, sodass der neueste Match eingefügt wird. Diese spezielle Unterart ist in der Zählung der gesamten 100%-Matches bereits enthalten.

- 100%-Match / partieller Match (Absatzkontext): In einem Absatz wird für bestimmte Teilsegmente ein 100%-Match gefunden, allerdings nicht für den gesamten Absatz. Ist die Option eines Platzhalters (##NO_MATCH##) deaktiviert, werden diese Matches nicht in der Vorübersetzung berücksichtigt; der gesamte Absatz bleibt dann unübersetzt. Bei aktivierter Verwendung von Platzhaltern werden die vorhandenen Teilsegmente vorübersetzt und für die fehlenden Textteile der Platzhalter eingefügt. Diese partiellen 100%-Matches sind in der Gesamtzählung ebenfalls enthalten.

- 100%-Match (MÜ): Für den Ausgangstext ergibt sich ein Suchtreffer durch Anfrage an ein angeschlossenes MÜ-System (z. B. Google Translator). Diese Unterart ist nicht in den gesamt ausgewiesenen 100%-Matches enthalten, sondern als gesonderte Kategorie aufgeführt.
Eine weitere, erwähnenswerte Matchwertkategorie ist Match / nicht eingefügt (Absatzvalidierung fehlgeschlagen): Hierbei handelt es sich um eine Übersetzungseinheit, die aufgrund von möglichen, zukünftigen Problemen bei der Zielsegment- oder Zielabsatzvalidierung nicht eingefügt wurde. Das vorhandene Match kann z. B. fehlende Tags oder Präfixkomponenten, zu langen Zieltext (überschrittene Längenbeschränkung) und falsche Versionsangaben enthalten oder zu einer fehlgeschlagenen Wohlgeformtheits- bzw. Strukturprüfung führen. Durch das Ignorieren dieser Segmente in der Vorübersetzung wird diese Konsequenz so gut wie möglich vermieden. Betroffen sind Tagged ML-Formate, Ressource-Dateien, etc. Matches der o. g. Art sind jeweils in den entsprechenden Matchwertkategorien enthalten.
Höher – weiter – besser?
Von noch höherer Qualität als ein 100%-Match sind Struktur-Matches und Kontext-Matches. Bei beiden Matchwertkategorien stimmen nicht nur Text und Formatierung exakt überein, sie zeichnen sich auch durch weitere übereinstimmende Eigenschaften aus, die eine sichere Verwendung der bereits gespeicherten Übersetzungen garantieren. So ist bei einem Kontext-Match nicht nur das betroffene Segment, sondern auch das vorangegangene und das nachfolgende Segment identisch – der Kontext ist gleich geblieben. Diese, die betroffene Übersetzungseinheit umgebenden Segmente werden über die IDs der in crossTank gespeicherten Übersetzungseinheiten ermittelt. Ausnahmen gibt es bei Segmenten am Textanfang oder -ende, bei denen respektive das vorangegangene bzw. nachfolgende Segment für die Einstufung als Kontext-Match entfällt.
Das Struktur-Match dagegen zeichnet sich zusätzlich zu einem 100%-Match durch ein übereinstimmendes Strukturattribut aus. Dieses Strukturattribut enthält Informationen zur Position des Textsegments im vorliegenden Text, z. B. ob es sich um ein Aufzählungselement, eine Kapitelüberschrift oder eine Software-Schaltfläche handelt. Aktuell werden diese Attribute für die Tagged ML-Formate HTML, SGML und XML, sowie für manche konvertierte Formate dieser Art unterstützt. Strukturattribute können individuell in den Systemeinstellungen von Across angelegt werden (standardmässig sind die Attribute Überschrift, Absatz, Listenelement und Schaltfläche bereits vorhanden).
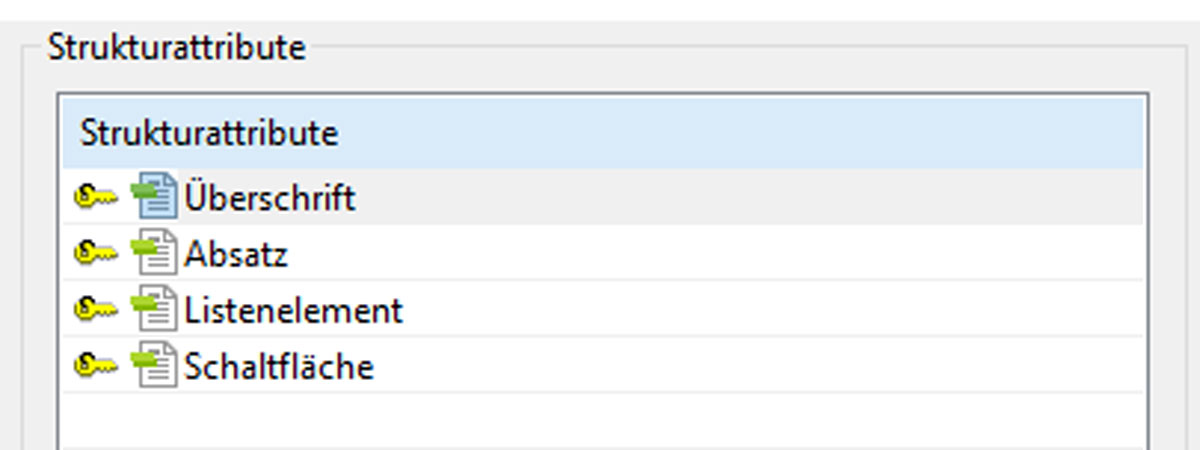
Nach Anlage eines Attributs kann dieses einem bestimmten Tagged-ML-Element zugewiesen werden (z. B. <heading> = Überschrift). Wird dieses Segment nach abgeschlossener Übersetzung in crossTank gespeichert, wird auch das dazugehörige Strukturattribut vermerkt und führt bei Folgeaufträgen zu einer zielgenauen Weiterverwendung der vorhandenen Übersetzungseinheit. </heading>
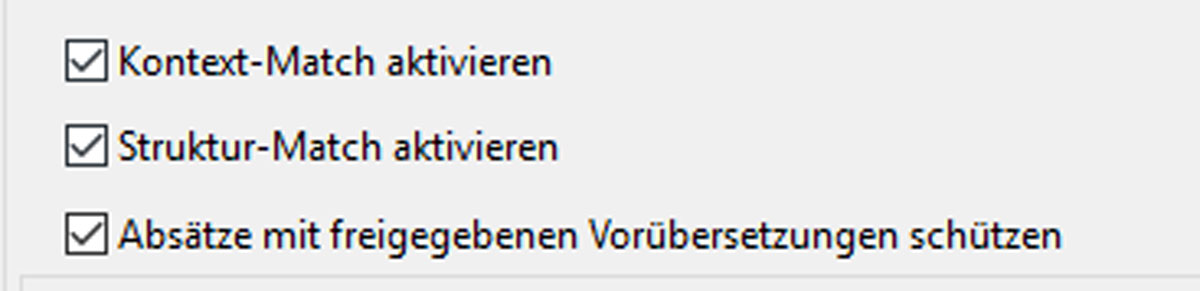
Die Suche nach sowohl Kontext- als auch Struktur-Matches muss in den Profileinstellungen bewusst aktiviert werden. Zudem können hier Abzüge (Penalties) für ein fehlendes Kontext-Match oder ein abweichendes Strukturattribut bei sonst vollständiger Übereinstimmung bestimmt werden. Beide Matchwertkategorien können zudem auch kombiniert werden und so ein noch besseres Match bilden: das Kontext- und Struktur-Match.
Matches en masse
Nicht zu vergessen sind Matches, die aus einem zweisprachigen Dokument eingefügt worden sind. Hierbei kommt es zu einer Vorübersetzung bestimmter Ausgangssegmente mit Übersetzungen aus einer zweisprachigen XLIFF-Datei. Diese Datei muss hierbei nicht komplett übersetzt sein, sondern kann auch nur ausgewählte Zielsegmente enthalten. Für Matches dieser Art wird ein eigener Bearbeitungszustand bzw. ein eigenes Icon in crossDesk vergeben. Ihr Sonderstatus lässt sich auch darauf zurückführen, dass sie Vorrang vor der 'regulären' Vorübersetzung haben. Falls eine Vorübersetzung durch eine zweisprachige XLIFF-Datei unerwünscht ist, z. B. bei rein ausgangssprachlichen Exporten aus einem CMS, in denen für die Übersetzung auch in der Zielsprache der ausgangssprachliche Text eingefügt wurde, kann dieser Vorgang unterdrückt werden.
Zu nennen sind auch geschützte Matches, d. h. in crossTank vorhandene Übersetzungseinheiten, denen der Status 'Freigegeben' zugeordnet wurde. Übersetzungseinheiten dieser Art werden bei jeglicher Vorübersetzung (regulär bei Projektanlage, manuell ausgelöst auf Projekt- oder Aufgabenebene oder on the fly in crossDesk) berücksichtigt und erhalten in der Regel den finalen Absatzzustand des dem Projekt zugrundeliegenden Workflows. Die eingefügten Übersetzungen sind dann nur mit speziellen Benutzerrechten editierbar. Diese Tatsache sollte bei der Vergabe des 'Freigegeben'-Status sowie der Verwendung von geschützten Matches in der Vorübersetzung unbedingt berücksichtigt werden; empfehlenswert ist dieses Vorgehen nur bei wirklich allgemeingültigen Übersetzungen, die kontextunabhängig ohne jegliche stilistische oder inhaltliche Anpassungen in verschiedensten Dokumenten verwendet werden können.
Wir hoffen sehr, dass dieser Artikel Ihnen die Matchwerte in Across näherbringen bzw. etwaige Unklarheiten bereinigen konnte! In weiteren Artikeln werden wir Ihnen noch die Analysewerte in SDL Trados Studio näherbringen und einen Vergleich zwischen den beiden CAT-Tools ziehen.
Auf frohes Analysieren!
Quelle: Across-Hilfe (inkl. Match-Wert-Icon, Rest Snips selber erstellt)